
NVIDIA NeMo Framework

Spesifikasjoner
- Produktnavn: NVIDIA NeMo Framework
- Berørte plattformer: Windows, Linux, macOS
- Berørte versjoner: Alle versjoner før 24
- Sikkerhetssårbarhet: CVE-2025-23360
- Grunnpoeng for risikovurdering: 7.1 (CVSS v3.1)
Produktbruksinstruksjoner
Installasjon av sikkerhetsoppdatering:
Følg disse trinnene for å beskytte systemet ditt:
- Last ned den siste utgivelsen fra NeMo-Framework-Launcher Releases-siden på GitHub.
- Gå til NVIDIA Product Security for mer informasjon.
Sikkerhetsoppdateringsdetaljer:
Sikkerhetsoppdateringen adresserer et sikkerhetsproblem i NVIDIA NeMo Framework som kan føre til kodeutførelse og data tampering.
Programvareoppdatering:
Hvis du bruker en tidligere filialutgivelse, anbefales det å oppgradere til den nyeste filialutgivelsen for å løse sikkerhetsproblemet.
Overview
NVIDIA NeMo Framework er et skalerbart og skybasert generativt AI-rammeverk bygget for forskere og utviklere som jobber med Store språkmodeller, Multimodal, og Tale AI (f.eks Automatisk talegjenkjenning og Tekst-til-tale). Det gjør det mulig for brukere å effektivt lage, tilpasse og distribuere nye generative AI-modeller ved å utnytte eksisterende kode og forhåndstrente modellsjekkpunkter.
Oppsettinstruksjoner: Installer NeMo Framework
NeMo Framework gir ende-til-ende-støtte for utvikling av store språkmodeller (LLMs) og Multimodal Models (MMs). Det gir fleksibiliteten til å brukes lokalt, i et datasenter eller med din foretrukne skyleverandør. Den støtter også kjøring i SLURM- eller Kubernetes-aktiverte miljøer.

Datakurering
NeMo-kurator [1] er et Python-bibliotek som inkluderer en pakke med moduler for datautvinning og syntetisk datagenerering. De er skalerbare og optimalisert for GPU-er, noe som gjør dem ideelle for å kurere data på naturlig språk for å trene eller finjustere LLM-er. Med NeMo Curator kan du effektivt trekke ut høykvalitetstekst fra omfattende råmateriale web datakilder.
Opplæring og tilpasning
NeMo Framework gir verktøy for effektiv opplæring og tilpasning av LLM-er og multimodale modeller. Den inkluderer standardkonfigurasjoner for dataklyngeoppsett, datanedlasting og modellhyperparametere, som kan justeres for å trene på nye datasett og modeller. I tillegg til forhåndstrening, støtter NeMo både Supervised Fine-Tuning (SFT) og Parameter Efficient Fine-Tuning (PEFT) teknikker som LoRA, Ptuning og mer.
To alternativer er tilgjengelige for å starte opplæring i NeMo – ved å bruke NeMo 2.0 API-grensesnittet eller med NeMo Run.
- Med NeMo Run (anbefalt): NeMo Run gir et grensesnitt for å strømlinjeforme konfigurasjon, utførelse og administrasjon av eksperimenter på tvers av ulike datamiljøer. Dette inkluderer lansering av jobber på arbeidsstasjonen din lokalt eller på store klynger – både SLURM-aktivert eller Kubernetes i et skymiljø.
- Førtrening og PEFT Quickstart med NeMo Run
- Bruk av NeMo 2.0 API: Denne metoden fungerer bra med et enkelt oppsett som involverer små modeller, eller hvis du er interessert i å skrive din egen tilpassede datalaster, treningsløkker eller endre modelllag. Det gir deg mer fleksibilitet og kontroll over konfigurasjoner, og gjør det enkelt å utvide og tilpasse konfigurasjoner programmatisk.
-
Training Quickstart med NeMo 2.0 API
-
Migrerer fra NeMo 1.0 til NeMo 2.0 API
-
Justering
- NeMo-Aligner [1] er et skalerbart verktøysett for effektiv modelljustering. Verktøysettet har støtte for state-of-the-art modelljusteringsalgoritmer som SteerLM, DPO, Reinforcement Learning from Human Feedback (RLHF), og mye mer. Disse algoritmene gjør det mulig for brukere å justere språkmodeller for å være tryggere, harmløse og nyttige.
- Alle NeMo-Aligner-sjekkpunktene er krysskompatible med NeMo-økosystemet, noe som gir mulighet for ytterligere tilpasning og slutningsdistribusjon.
Trinn-for-trinn arbeidsflyt for alle tre fasene av RLHF på en liten GPT-2B-modell:
- SFT opplæring
- Belønn modelltrening
- PPO opplæring
I tillegg demonstrerer vi støtte for forskjellige andre nye justeringsmetoder:
- DPO: en lettvektsjusteringsalgoritme sammenlignet med RLHF med en enklere tapsfunksjon.
- Selvspill Finjustering (SPIN)
- SteerLM: en teknikk basert på conditioned-SFT, med styrbar utgang.
Sjekk ut dokumentasjonen for mer informasjon: Opprettingsdokumentasjon
Multimodale modeller
- NeMo Framework gir optimert programvare for å trene og distribuere toppmoderne multimodale modeller på tvers av flere kategorier: Multimodale språkmodeller, Vision-Language Foundations, Text-to-Image-modeller og utover 2D-generering ved bruk av Neural Radiance Fields (NeRF).
- Hver kategori er designet for å imøtekomme spesifikke behov og fremskritt innen feltet, og utnytter banebrytende modeller for å håndtere et bredt spekter av datatyper, inkludert tekst, bilder og 3D-modeller.
Note
Vi migrerer støtte for multimodale modeller fra NeMo 1.0 til NeMo 2.0. Hvis du vil utforske dette domenet i mellomtiden, vennligst se dokumentasjonen for NeMo 24.07 (forrige) utgivelse.
Utplassering og inferens
NeMo Framework gir ulike veier for LLM-slutning, imøtekommer ulike distribusjonsscenarier og ytelsesbehov.
Distribuer med NVIDIA NIM
- NeMo Framework integreres sømløst med modelldistribusjonsverktøy på bedriftsnivå gjennom NVIDIA NIM. Denne integrasjonen er drevet av NVIDIA TensorRT-LLM, som sikrer optimalisert og skalerbar inferens.
- For mer informasjon om NIM, besøk NVIDIA webnettstedet.
Distribuer med TensorRT-LLM eller vLLM
- NeMo Framework tilbyr skript og API-er for å eksportere modeller til to inferensoptimaliserte biblioteker, TensorRT-LLM og vLLM, og for å distribuere den eksporterte modellen med NVIDIA Triton Inference Server.
- For scenarier som krever optimalisert ytelse, kan NeMo-modeller utnytte TensorRT-LLM, et spesialisert bibliotek for å akselerere og optimalisere LLM-slutninger på NVIDIA GPUer. Denne prosessen innebærer å konvertere NeMo-modeller til et format som er kompatibelt med TensorRT-LLM ved å bruke nemo.export-modulen.
- LLM-distribusjon overview
- Distribuer NeMo Large Language Models med NIM
- Distribuer NeMo Large Language Models med TensorRT-LLM
- Distribuer NeMo Large Language Models med vLLM
Støttede modeller
Store språkmodeller
| Store språkmodeller | Fortrening og SFT | PEFT | Justering | FP8 Training Convergence | TRT/TRTLLM | Konverter til og fra Hugging Face | Evaluering |
|---|---|---|---|---|---|---|---|
| Lama3 8B/70B, Lama3.1 405B | Ja | Ja | x | Ja (delvis bekreftet) | Ja | Både | Ja |
| Mixtral 8x7B/8x22B | Ja | Ja | x | Ja (ubekreftet) | Ja | Både | Ja |
| Nemotron 3 8B | Ja | x | x | Ja (ubekreftet) | x | Både | Ja |
| Nemotron 4 340B | Ja | x | x | Ja (ubekreftet) | x | Både | Ja |
| Baichuan2 7B | Ja | Ja | x | Ja (ubekreftet) | x | Både | Ja |
| ChatGLM3 6B | Ja | Ja | x | Ja (ubekreftet) | x | Både | Ja |
| Gemma 2B/7B | Ja | Ja | x | Ja (ubekreftet) | Ja | Både | Ja |
| Gemma2 2B/9B/27B | Ja | Ja | x | Ja (ubekreftet) | x | Både | Ja |
| Mamba2 130M/370M/780M/1.3B/2.7B/8B/ Hybrid-8B | Ja | Ja | x | Ja (ubekreftet) | x | x | Ja |
| Phi3 mini 4k | x | Ja | x | Ja (ubekreftet) | x | x | x |
| Qwen2 0.5B/1.5B/7B/72B | Ja | Ja | x | Ja (ubekreftet) | Ja | Både | Ja |
| StarCoder 15B | Ja | Ja | x | Ja (ubekreftet) | Ja | Både | Ja |
| StarCoder2 3B/7B/15B | Ja | Ja | x | Ja (ubekreftet) | Ja | Både | Ja |
| BERT 110M/340M | Ja | Ja | x | Ja (ubekreftet) | x | Både | x |
| T5 220M/3B/11B | Ja | Ja | x | x | x | x | x |
Visjonsspråkmodeller
| Visjonsspråkmodeller | Fortrening og SFT | PEFT | Justering | FP8 Training Convergence | TRT/TRTLLM | Konverter til og fra Hugging Face | Evaluering |
|---|---|---|---|---|---|---|---|
| NeVA (LLaVA 1.5) | Ja | Ja | x | Ja (ubekreftet) | x | Fra | x |
| Lama 3.2 Vision 11B/90B | Ja | Ja | x | Ja (ubekreftet) | x | Fra | x |
| LLaVA Next (LLaVA 1.6) | Ja | Ja | x | Ja (ubekreftet) | x | Fra | x |
Innebyggingsmodeller
| Innbygging av språkmodeller | Fortrening og SFT | PEFT | Justering | FP8 Training Convergence | TRT/TRTLLM | Konverter til og fra Hugging Face | Evaluering |
|---|---|---|---|---|---|---|---|
| SBERT 340M | Ja | x | x | Ja (ubekreftet) | x | Både | x |
| Lama 3.2 Innebygging 1B | Ja | x | x | Ja (ubekreftet) | x | Både | x |
World Foundation Models
| World Foundation Models | Ettertrening | Akselerert slutning |
|---|---|---|
| Cosmos-1.0-Diffusion-Text2World-7B | Ja | Ja |
| Cosmos-1.0-Diffusion-Text2World-14B | Ja | Ja |
| Cosmos-1.0-Diffusion-Video2World-7B | Kommer snart | Kommer snart |
| Cosmos-1.0-Diffusion-Video2World-14B | Kommer snart | Kommer snart |
| Cosmos-1.0-Autoregressiv-4B | Ja | Ja |
| Cosmos-1.0-Autoregressive-Video2World-5B | Kommer snart | Kommer snart |
| Cosmos-1.0-Autoregressiv-12B | Ja | Ja |
| Cosmos-1.0-Autoregressive-Video2World-13B | Kommer snart | Kommer snart |
Note
NeMo støtter også fortrening for både diffusjons- og autoregressive arkitekturer text2world grunnmodeller.
Tale AI
Å utvikle konversasjons-AI-modeller er en kompleks prosess som involverer å definere, konstruere og trene modeller innenfor bestemte domener. Denne prosessen krever vanligvis flere iterasjoner for å oppnå et høyt nivå av nøyaktighet. Det involverer ofte flere iterasjoner for å oppnå høy nøyaktighet, finjustering av ulike oppgaver og domenespesifikke data, sikring av treningsytelse og forberedelse av modeller for slutningsdistribusjon.
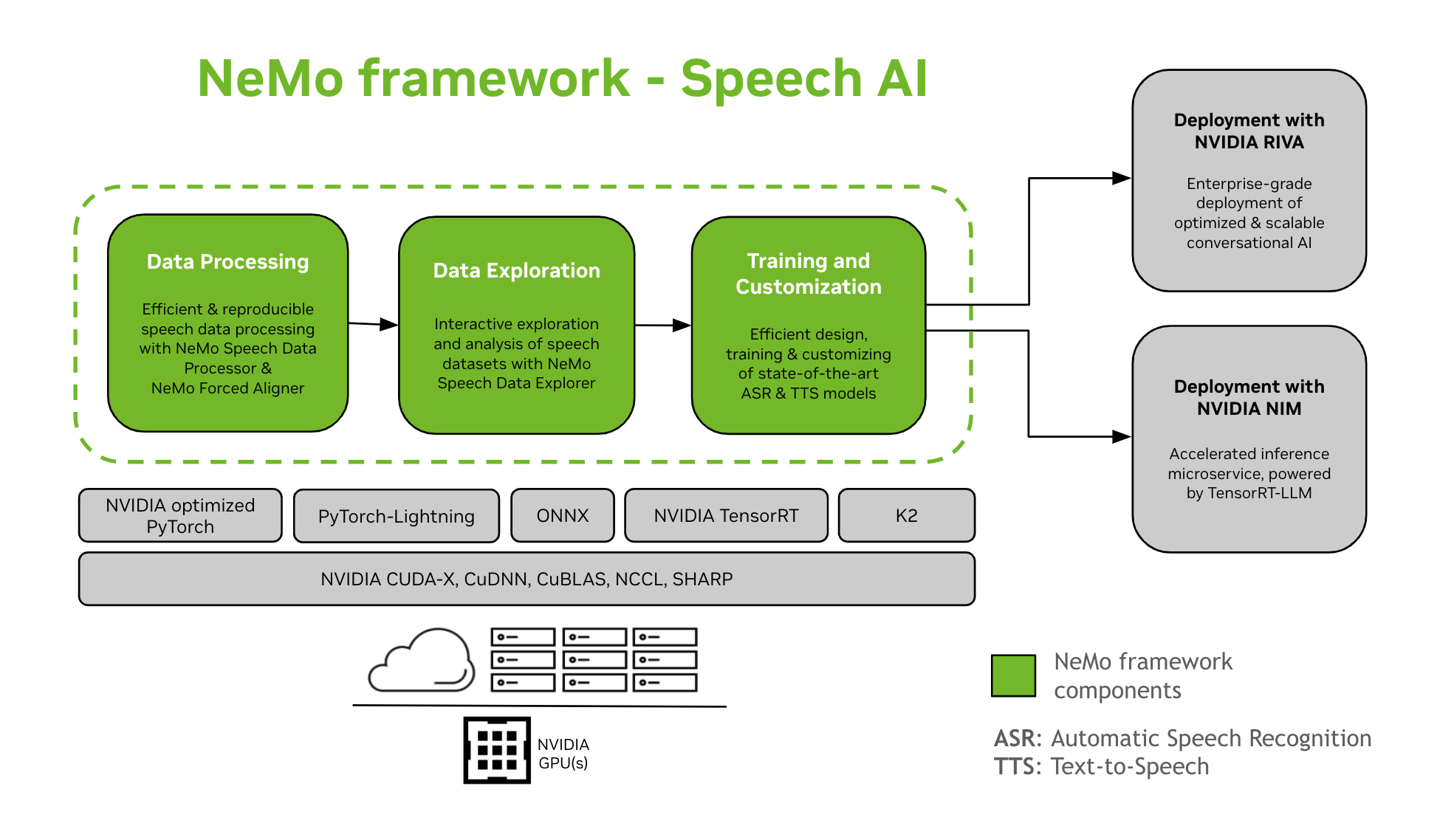
NeMo Framework gir støtte for opplæring og tilpasning av Speech AI-modeller. Dette inkluderer oppgaver som automatisk talegjenkjenning (ASR) og tekst-til-tale (TTS) syntese. Det gir en jevn overgang til produksjonsdistribusjon på bedriftsnivå med NVIDIA Riva. For å hjelpe utviklere og forskere inkluderer NeMo Framework toppmoderne forhåndstrente sjekkpunkter, verktøy for reproduserbar taledatabehandling og funksjoner for interaktiv utforskning og analyse av taledatasett. Komponentene i NeMo Framework for Speech AI er som følger:
Opplæring og tilpasning
NeMo Framework inneholder alt som trengs for å trene og tilpasse talemodeller (ASR, Taleklassifisering, Høyttalergjenkjenning, Diaarisering av høyttaler, og TTS) på en reproduserbar måte.
SOTA forhåndstrente modeller
- NeMo Framework gir state-of-the-art oppskrifter og forhåndstrente sjekkpunkter av flere ASR og TTS modeller, samt instruksjoner om hvordan du laster dem.
- Taleverktøy
- NeMo Framework gir et sett med verktøy som er nyttige for å utvikle ASR- og TTS-modeller, inkludert:
- NeMo Forced Aligner (NFA) for å generere token-, ord- og segmentnivå-tidsmålingamps tale i lyd ved hjelp av NeMos CTC-baserte modeller for automatisk talegjenkjenning.
- Taledatabehandler (SDP), et verktøysett for å forenkle taledatabehandling. Den lar deg representere databehandlingsoperasjoner i en konfigurasjon file, minimerer standardkode og tillater reproduserbarhet og delbarhet.
- Speech Data Explorer (SDE), en Dash-basert web applikasjon for interaktiv utforskning og analyse av taledatasett.
- Datasettopprettingsverktøy som gir funksjonalitet for å justere lang lyd files med de tilsvarende transkripsjonene og del dem i kortere fragmenter som er egnet for automatisk talegjenkjenning (ASR) modelltrening.
- Sammenligningsverktøy for ASR-modeller for å sammenligne prediksjoner av forskjellige ASR-modeller på ordnøyaktighet og ytringsnivå.
- ASR Evaluator for å evaluere ytelsen til ASR-modeller og andre funksjoner som Voice Activity Detection.
- Verktøy for tekstnormalisering for å konvertere tekst fra den skriftlige formen til den muntlige formen og omvendt (f.eks. "31st" vs "thirty first").
- Vei til distribusjon
- NeMo-modeller som har blitt opplært eller tilpasset ved hjelp av NeMo Framework kan optimaliseres og distribueres med NVIDIA Riva. Riva leverer containere og rorkart spesielt utviklet for å automatisere trinnene for utplassering av trykknapper.
Andre ressurser
- NeMo: Hovedlageret for NeMo Framework
- NeMo–Løp: Et verktøy for å konfigurere, starte og administrere maskinlæringseksperimentene dine.
- NeMo-Aligner: Skalerbart verktøysett for effektiv modelljustering
- NeMo-kurator: Skalerbart dataforbehandlings- og kurasjonsverktøysett for LLM-er
Engasjer med NeMo-fellesskapet, still spørsmål, få støtte eller rapporter feil.
- NeMo-diskusjoner
- NeMo-problemer
Programmeringsspråk og rammer
- Python: Hovedgrensesnittet for å bruke NeMo Framework
- Pytorch: NeMo Framework er bygget på toppen av PyTorch
Lisenser
- NeMo Github repo er lisensiert under Apache 2.0-lisensen
- NeMo Framework er lisensiert under NVIDIA AI-PRODUKTAVTALEN. Ved å trekke og bruke beholderen godtar du vilkårene og betingelsene i denne lisensen.
- NeMo Framework-beholderen inneholder Llama-materiale underlagt Meta Llama3 Community License Agreement.
Fotnoter
For øyeblikket er støtte for NeMo Curator og NeMo Aligner for multimodale modeller et arbeid under arbeid og vil være tilgjengelig snart.
FAQ
Spørsmål: Hvordan kan jeg sjekke om systemet mitt er berørt av sårbarheten?
A: Du kan sjekke om systemet ditt er berørt ved å bekrefte versjonen av NVIDIA NeMo Framework som er installert. Hvis det er under versjon 24, kan systemet ditt være sårbart.
Spørsmål: Hvem rapporterte sikkerhetsproblemet CVE-2025-23360?
A: Sikkerhetsproblemet ble rapportert av Or Peles – JFrog Security. NVIDIA erkjenner deres bidrag.
Spørsmål: Hvordan kan jeg motta fremtidige sikkerhetsbulletiner?
A: Besøk NVIDIA Product Security-siden for å abonnere på sikkerhetsbulletinvarslinger og holde deg informert om produktsikkerhetsoppdateringer.
Dokumenter / Ressurser
 | NeMo Framework |
Referanser
- Brukerhåndbokmanual.tools